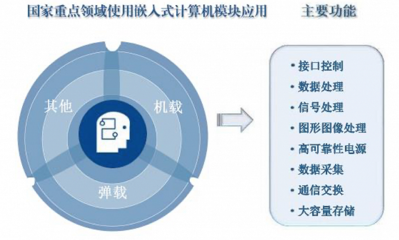
人工智能项目的成功极大程度上依赖于高质量的数据处理流程。数据处理是AI项目开发的核心环节,通常包括数据收集、数据清洗、数据标注、数据增强和数据划分等步骤。
数据收集是基础。开发者需要根据项目目标从公开数据集、企业内部数据或网络爬虫等渠道获取原始数据。例如,图像识别项目可能需要收集大量带标签的图片,而自然语言处理项目则需要文本语料库。数据来源的多样性和代表性直接影响模型的泛化能力。
接下来是数据清洗,这一步骤至关重要。原始数据往往包含噪声、缺失值或异常值,需要通过去重、填充缺失值、纠正错误等方式进行清理。例如,在文本数据中,可能需要移除特殊字符或统一日期格式;在图像数据中,则需调整尺寸或去除模糊图片。清洗后的数据能显著提升模型训练的稳定性。
数据标注是监督学习项目的关键。对于分类、检测或分割任务,数据需要被人工或半自动工具标记。例如,在目标检测中,标注人员会在图像中框出物体并指定类别;在情感分析中,文本会被标注为正面、负面或中性。高质量的标注数据是模型准确性的保证,但标注过程通常耗时且成本高昂。
数据增强则用于扩展数据集规模,特别是在数据量不足时。通过旋转、裁剪、添加噪声等方法对现有数据进行变换,可以增加模型的鲁棒性。例如,在图像识别中,对同一张图片进行亮度调整或翻转,能模拟不同场景下的输入。数据增强不仅能缓解过拟合,还能提升模型在真实环境中的表现。
数据划分将处理后的数据分为训练集、验证集和测试集。通常采用70-15-15或类似比例,确保模型在未见过的数据上得到公正评估。训练集用于模型学习,验证集用于调参,测试集则用于最终性能评估。合理的划分能有效避免数据泄露,保证结果的可靠性。
数据处理是人工智能项目开发的基石。一个系统化的数据处理流程不仅能提升模型性能,还能加速项目迭代。开发者应重视每个环节,结合具体需求选择合适工具和方法,以构建高效、可靠的AI系统。