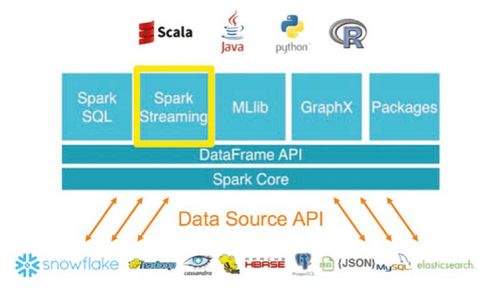
在当今数据驱动的时代,实时数据处理能力已成为企业获取竞争优势的关键。Apache Spark,作为一个统一的分析引擎,凭借其卓越的流数据处理模块——Spark Streaming(以及其进化版Structured Streaming),为构建低延迟、高吞吐、高容错的实时数据处理应用提供了强大的解决方案。
一、Spark流数据处理的核心概念
Spark流数据处理并非传统的逐条记录处理,而是采用一种被称为“微批处理(Micro-batch)”的模型。它将连续的实时数据流,按时间间隔(如1秒、2秒)切分成一系列小的、确定性的批处理作业(即RDD或DataFrame),然后利用Spark核心引擎强大的批处理能力对这些小批次数据进行快速计算。这种设计巧妙地在流处理的实时性和批处理的可靠性、易用性之间取得了平衡。
Structured Streaming 在此基础上更进一步,它将无限增长的实时数据流视为一张持续追加的表,用户可以使用熟悉的Dataset/DataFrame API进行查询。这种声明式的API将开发者从复杂的容错、状态管理细节中解放出来,专注于业务逻辑。
二、数据处理的关键环节与技术
一个完整的Spark流数据处理管道通常包含以下几个核心环节:
- 数据接入(Ingestion):Spark Streaming可以从多种实时数据源接入数据,如Kafka、Flume、Kinesis,以及TCP Socket等。与Kafka的集成尤为紧密和高效,是生产环境中最常见的组合。
- 核心转换与计算(Transformation & Computation):这是数据处理的“大脑”。开发者可以利用丰富的转换操作(如
map、filter、join、groupBy)和窗口操作(滑动窗口、滚动窗口)对数据进行清洗、聚合、关联等复杂计算。例如,可以计算最近5分钟内某商品的点击量,或者将实时用户行为日志与静态用户画像表进行关联分析。
- 状态管理(State Management):对于需要跨批次追踪信息的应用(如用户会话分析、累加计数),Structured Streaming提供了内置的、容错的状态管理机制(如
mapGroupsWithState、flatMapGroupsWithState),确保即使发生故障,状态也能精确恢复。
- 结果输出(Sink):处理后的结果可以输出到多种外部系统,包括文件系统(如HDFS、S3)、数据库(如MySQL、Cassandra)、消息队列(如Kafka)以及控制台,以供下游系统使用、可视化或持久化存储。
- 容错与一致性(Fault Tolerance & Exactly-Once Semantics):这是生产系统的生命线。Spark通过预写日志(Write-Ahead Log)和检查点(Checkpointing)机制,结合可靠的数据源和输出端,能够实现端到端的“精确一次”处理语义,确保数据既不丢失也不重复。
三、典型应用场景
- 实时监控与告警:实时分析服务器日志、应用性能指标(APM),及时发现异常并触发告警。
- 实时推荐系统:根据用户实时点击、浏览行为,即时更新用户兴趣模型,调整推荐结果。
- 金融风控:实时监控交易流水,利用规则或模型在毫秒级内识别欺诈行为。
- 物联网(IoT)数据处理:处理海量传感器上传的时序数据,进行实时聚合、分析与预测性维护。
- 实时仪表盘:为运营人员提供实时更新的业务关键指标(KPI)视图。
四、挑战与最佳实践
尽管Spark流处理功能强大,但在实际应用中仍需注意:
- 延迟与吞吐量的权衡:更小的批处理间隔带来更低延迟,但会增加调度开销,可能影响吞吐。需要根据业务需求调整。
- 资源规划:流处理作业是7x24小时长时运行的服务,需要合理分配Executor内存、核心数,并设置动态资源分配以提高集群利用率。
- 背压(Backpressure)处理:当数据流入速度超过处理速度时,系统需具备动态调整接收速率的能力,Spark Streaming通过反压机制来自动调节。
- 监控与运维:需密切监控批处理时间、调度延迟、积压批次等关键指标,确保作业稳定运行。
###
Apache Spark的流数据处理框架,特别是Structured Streaming,通过将流计算抽象为对无限表的增量查询,极大地简化了实时应用的开发复杂度。它结合了批处理的强大功能和流处理的实时性,为处理高速增长的数据流提供了一个统一、可扩展且高可靠的一站式平台。掌握Spark流数据处理,意味着能够驾驭数据的“流速”,从实时数据中即时提炼价值,驱动业务快速智能决策。